⏹ SORT
Syntaxe
SORT [/R] [/+n] [/M kilo-octets] [/L locale] [/REC octets_enregistrement]
[[lecteur1:][chemin1]nom_fichier1] [/T [lecteur2:][chemin2]]
[/O [lecteur3:][chemin3]nom_fichier3]
/+n Spécifie à partir de quel caractère, n, commencer chaque comparaison.
/+3 Indique que chaque comparaison doit commencer au 3ème caractère de chaque
ligne. Les lignes de moins de n caractères sont révisées avant les autres lignes.
Par défaut, les comparaisons commencent au premier caractère de chaque ligne.
/L[OCALE] locale Remplace les paramètres régionaux par défaut du système avec
ceux spécifiés. Les paramètres ""C"" donnent la séquence de révision la plus
rapide et sont actuellement le seul choix. Le tri ne tient pas compte de la casse.
/M[EMORY] kilo-octets Spécifie la quantité en kilo-octets de mémoire principale
à utiliser pour le tri. La taille mémoire ne peut jamais être inférieure à 160
kilo-octets. Si la taille mémoire est spécifiée, la quantité exacte sera
utilisée pour le tri, indépendamment de la quantité de mémoire principale disponible.
De meilleurs résultats sont en général obtenus en n'indiquant pas de taille
mémoire. Par défaut, le tri sera fait en une seule passe (pas de fichier
temporaire) si la taille mémoire maximale par défaut est suffisante, sinon le
tri sera fait en deux passes (les données partiellement triées étant stockées
dans un fichier temporaire) afin que les quantités de mémoire utilisées pour le
tri et la fusion soient égales. La taille mémoire maximale par défaut est fixée
à 90% de la mémoire principale disponible si entrée et sortie sont des fichiers, et à 45% dans les autres cas.
/REC[ORD_MAXIMUM] caractères Spécifie le nombre maximal de caractères dans un enregistrement (par défaut 4096, maximum 65535).
/R[EVERSE] Inverse l'ordre de tri, c'est-à-dire, effectue le tri de Z à A, puis de 9 à 0.
[lecteur1:][chemin1]nom_fichier1 Spécifie quel fichier trier. S'il n'est pas
spécifié, c'est l'entrée standard qui est triée.
Spécifier le fichier d'entrée est plus rapide que de rediriger ce fichier comme entrée standard.
/T[EMPORARY] [lecteur2:][chemin2] Spécifie le chemin d'accès au répertoire dans
lequel le tri doit stocker ses données, dans le cas où ces données ne peuvent
être contenues dans la mémoire principale. Par défaut, c'est le répertoire temporaire du système qui est utilisé.
/O[UTPUT] [lecteur3 :][chemin3]nom_fichier3 Spécifie le fichier dans lequel
l'entrée triée doit être stockée. S'il n'est pas spécifié, les données sont
écrites dans la sortie standard.
Spécifier le fichier de sortie est plus rapide que de rediriger la sortie
standard vers le même fichier.
La commande SORT trie les critères alphanumériques. Hormis le critère positionnel /+n, il n'est pas possible de donner un champ comme clef de tri.
Les tris sur des fichiers à enregistrement de longueurs fixes sont donc plus aisés que pour les fichiers à enregistrement de tailles variables.
Exemple 1 de tri sur enregistrement à taille fixe
Le fichier vehicule3.txt contient des enregistrements à tailles fixes. On va pouvoir le trier aisément sur le prix qui est en position 20 de chaque enregistrement.
type vehicule3.txt Marque Modèle Prix Peugeot 308 27500 Renault Clio 18900 Citroen C5 26500 Peugeot 2008 25500 Renault Captur 24500 Citroen C3 17900 Renault Megane 27500 Citroen C4 23900 Peugeot 208 19900 sort /+20 vehicule3.txt Citroen C3 17900 Renault Clio 18900 Peugeot 208 19900 Citroen C4 23900 Renault Captur 24500 Peugeot 2008 25500 Citroen C5 26500 Peugeot 308 27500 Renault Megane 27500 Marque Modèle Prix
Exemple 2 de tri sur enregistrement à taille variable
Sur ce fichier, on ne peut pas trier sur le prix car il n'est pas toujours à la
même position sur chaque ligne du fichier.
Nous allons tenter de le trier sur la position du prix de l'enregistrement Citroen C3 qui
se situe en position 12. 😕
type vehicule2.txt Marque Modèle Prix Peugeot 308 27500 Renault Clio 18900 Citroen Berlingo 26500 Peugeot 2008 25500 Renault Captur 24500 Citroen C3 17900 Renault Megane 27500 Citroen C4 23900 Peugeot 208 19900 sort /+12 vehicule2.txt Peugeot 208 19900 Peugeot 308 27500 Citroen C3 17900 Citroen C4 23900 Peugeot 2008 25500 Renault Megane 27500 Marque Modèle Prix Citroen Berlingo 26500 Renault Clio 18900 Renault Captur 24500
💡
Vous l'avez compris, le terminal de commande n'est pas un champion du tri...
Nous aurons besoin de traiter les données lorsqu'on est confronté à des
enregistrements de tailles variables.
Exemple 3 de tri sur enregistrement à taille variable
Dans cet exemple, on a récupéré le fichier de toutes les capsules Gemini
connues. Nous souhaitons le trier par ordre croissant sur le nombre d'URL
contenus dans les capsules.
Ce fichier contient 3241 lignes non triées.
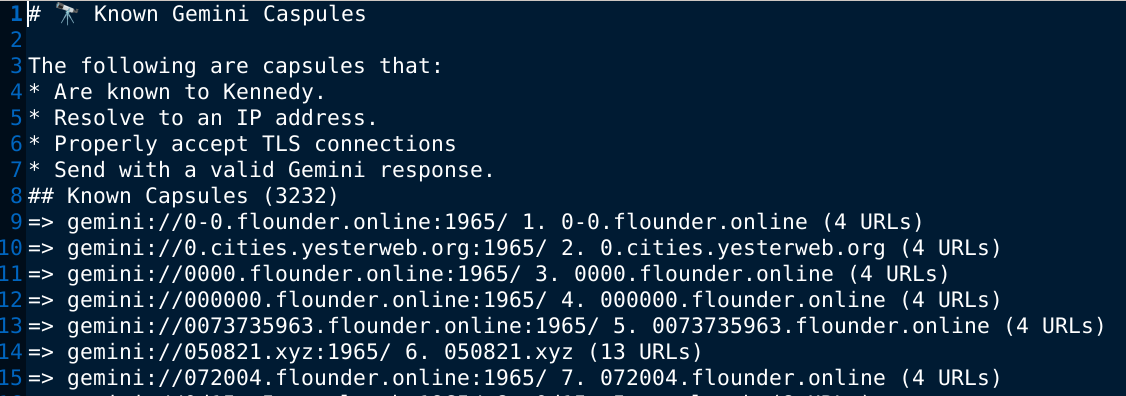{kind=link}
Alors comment faire ?
Nous allons analyser chaque ligne du fichier en sautant les 8 premières qui ne nous
intérrese pas.
On segmente ensuite chaque ligne pour extraire dans 2 tokens distincts les
informations utiles.
Le premier avec l'url de la capsule et le 2eme avec le nombre d'Urls.
Dans notre exemple, la variable NB récupère une chaine contenant une valeur
suivie du mot URLs. Exemple : 113 URLs
On traite donc la variable NB pour extraire la chaine URLs afin qu'elle ne
contiene que le nombre.
On va ensuite constituer un fichier temporaire TEMP.TXT qui aura la forme suivante :
Nombre d'URLS;=> gemini://adresse
Nombre d'URLS;=> gemini://adresse
Nombre d'URLS;=> gemini://adresse
...
Un problème est à prendre en compte.
La commande SORT ne trie que sur des valeurs alphanumériques. Ce qui veut dire
qu'une liste de nombre ne peut pas être trier comme tel mais le sera comme du texte.
Ainsi la liste suivante :
1002
101
31
3
309
2000
Sera triée comme suit :
1002
101
2000
3
309
31
Comment procéder ?
L'idée est de compléter la variable NB par des zéros non significatifs afin
que chaque valeur contiennent le même nombre de caractères.
De telle sorte nous aurons une liste de valeurs parfaitement formatées pour que
le tri alphaumérique fonctionne.
Considérer l'exemple suivant :
type fic.txt 1002 0101 0031 0003 0309 2000 sort fic.txt 0003 0031 0101 0309 1002 2000
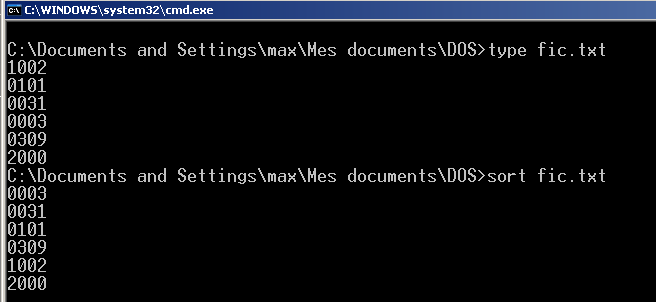{kind=link}
Le script 🏆
::GEMINI Known capsules sort
::Ce script tri le fichier gemini_known_capsules.txt par nombre d'adresses
::croissantes
SETLOCAL ENABLEDELAYEDEXPANSION
REM on s'assure que le fichier TEMP.TXT soit supprimé
IF EXIST TEMP.TXT DEL TEMP.TXT
REM Analyse du fichier gemini_known_capsules.txt
FOR /F "tokens=1,2 skip=8 delims=()" %%a in (gemini_known_capsules.txt) DO (
REM On récupère le token 2 dans NB
REM On enlève les 5 derniers caractères correspondant à la chaine URLs
SET NB=%%b
SET NB=!NB:~0,-5!
SET LEN=0
SET CAR=
REM On calcule la longueur du 2eme token mis dans la variable NB
FOR /L %%x in (10,-1,0) DO (
SET CAR=!NB:~%%x,1!
IF DEFINED CAR SET /A "LEN=LEN+1"
)
REM END contient le nombre de zéro à rajouter
SET /A "END = 10-!LEN!"
REM Ajoute les zéros nécessaires
SET ZERO=
FOR /L %%x IN (1,1,!END!) DO (
SET ZERO=!ZERO!0
)
REM Formate NB avec les zéros non significatifs
SET NB=!ZERO!!NB!
REM Ecris la ligne dans temp.txt
ECHO !NB!;%%a >> TEMP.TXT
)
REM Tri du fichier temp.txt et dirige la sortie dans TEMP2.TXT
SORT TEMP.TXT > TEMP2.TXT
REM SUPPRESSION DE TEMP.TXT
DEL TEMP.TXT
REM RENOMMAGE
REN TEMP2.TXT TEMP.TXT
2025-11-08 Known Gemini Caspules sorted by number of URL
𝗧𝗵𝗮𝘁'𝘀 𝗮𝗹𝗹 𝙁𝙤𝙡𝙠𝙨 ‼