BOM or not BOM ? 🐧
Mes pages GEMINI n'étaient pas collectées par l'agrégateur Antenna. J'ai comparé les pages qui fonctionnaient sans avoir de réponses à ce bug.
Mes pages étaient correctes et respectées le format Gemtext :
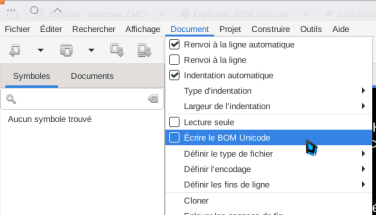
J'ai donc orienté mes recherches vers l'encodage UTF-8. Et là, j'ai compris que mon éditeur préféré, en l'occurence Geany, ecrivait le BOM.
Le BOM Unicode (Byte Order Mark) est un petit marqueur placé au début d’un fichier texte pour indiquer deux choses :
- L’encodage du fichier (UTF-8, UTF-16, UTF-32, etc.)
- L’ordre des octets (endianness) pour UTF-16 et UTF-32 : big-endian ou little-endian.
Il n’est pas une partie du texte, juste un indicateur pour le logiciel qui lit le fichier.
Alors que le codage de caractères UTF-8 ne pose pas de problème d'ordre des octets, l'indicateur d'ordre des octets est parfois utilisé pour déterminer qu'un texte est bien encodé en UTF-8.
C'est ce BOM qui posait un problème de reconnaissance dans les aggrégateurs.
Donc, éviter cela !
{kind=link}
🇬🇧🇬🇧🇬🇧🇬🇧
My GEMINI pages were not being collected by the Antenna aggregator. I compared the pages that worked, without getting any clear answers about the issue.
My pages were correct and followed the Gemtext format:
So I focused my investigation on the UTF-8 encoding. And then I realized that my preferred editor, Geany, was writing a BOM.
The Unicode BOM (Byte Order Mark) is a small marker placed at the beginning of a text file to indicate two things:
- The file’s encoding (UTF-8, UTF-16, UTF-32, etc.)
- The byte order (endianness) for UTF-16 and UTF-32: big-endian or little-endian.
It is not part of the text itself, just an indicator for the software reading the file.
Even though UTF-8 does not have byte-order issues, the presence of a BOM is sometimes used as a signal that the text is UTF-8 encoded.
This BOM was causing a recognition issue with the aggregators.
So, avoid it!
$ published: 2025-11-27 23:30:00 $